第四章:视频生成—Seedance
图生视频 · 文生视频 · 首尾帧 · Seedance 2.0 · 完整操作流程
🎯 4.0 生成流程
进入「AI视频」后,依次完成参考模式、模型选择、尺寸选择与时长设定(对应下文 4.1–4.5 各小节;其中 4.1.1 全能参考、4.1.2 智能多帧 紧接在 4.1 参考模式表之后)的确定。新手建议优先从 图生视频 入门:画面锚点明确,提示词侧重「动什么、怎么动」即可。下图为首屏「生成方式」区域截图。
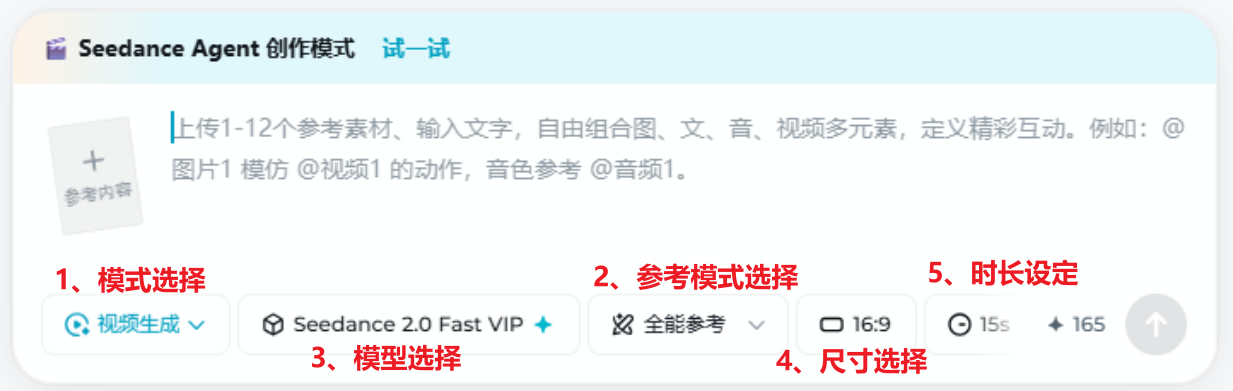
选择如何用参考素材驱动生成
选择视频模型与动态档位
选择画面比例与分辨率
设置生成秒数与积分预期
🖼️ 4.1 参考模式选择
参考模式决定「素材怎么参与生成」,且与当前视频模型强绑定:不同入口是否出现、是否可用完整能力,取决于所选模型版本。下图为三种参考入口:全能参考、首尾帧、智能多帧(名称与布局以客户端为准)。下表「模型支持」列汇总当前手册口径,仍以客户端界面为准。
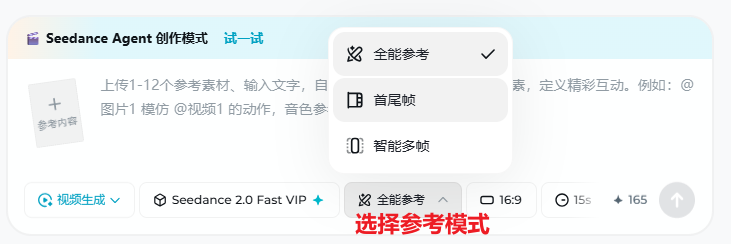
| 模块 | 核心作用 | 使用提示 | 模型支持 |
|---|---|---|---|
| 全能参考 | 多图、音/视频与文本协同,用 @引用 等方式精确指定各素材角色,适合 分镜叙事、运镜复刻、音乐卡点 等高控制需求 | 上传后务必在提示词中写清 @ 对应关系;素材数量与格式需符合模型限制 | 仅 Seedance 1.0 Fast(以客户端为准) |
| 首尾帧 | 分别指定 首帧与尾帧 画面,由模型 补全中间过渡,适合「从 A 状态到 B 状态」的硬切或渐变 | 两帧构图、人物位置与透视要可衔接;过渡逻辑写在提示词里更稳 | 各视频模型普遍支持(以客户端为准) |
| 智能多帧 | 在单图与首尾帧之间,用 多关键帧 辅助连续动作或段落叙事,由系统辅助 插值与衔接 | 关键帧之间变化不宜过大;适合小节拍、多姿势串联,具体能力随版本更新 | 仅 Seedance 2.0(以客户端为准) |
🔑 4.1.1 全能参考
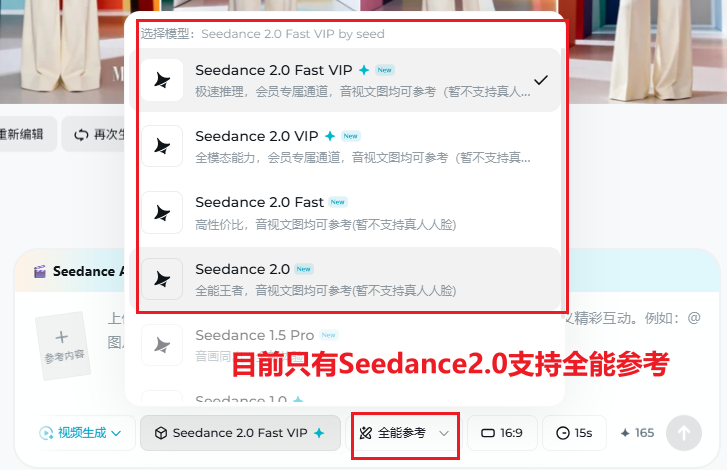
对照上表「全能参考」一行:在模型区选对视频模型后,通过多图 / 音视频与 @ 引用 精确约束分镜与素材角色。下图为模型区示意,便于与上表「模型支持」列对照。
下图为模型区示意。切换模型后,全能参考入口是否出现、能力是否完整可能变化;若与上表「模型支持」或实际界面不一致,以客户端为准。
目前 Seedance 2.0 系列均不支持真人人脸相关视频(如写实人像驱动、对口型等人像类成片;具体禁限售与合规规则以平台及客户端公示为准)。
上传素材后必须在提示词中用 @素材名 明确引用,否则模型无法理解素材用途。
常用 @ 引用写法
- @图片1 作为首帧,参考 @视频1 的运镜
- @图片1 的女生作为主角,@图片2 的男生作为配角
- 完全参考 @视频1 的所有运镜效果
- 参考 @音频1 的节奏进行音乐卡点
📎 4.1.2 智能多帧
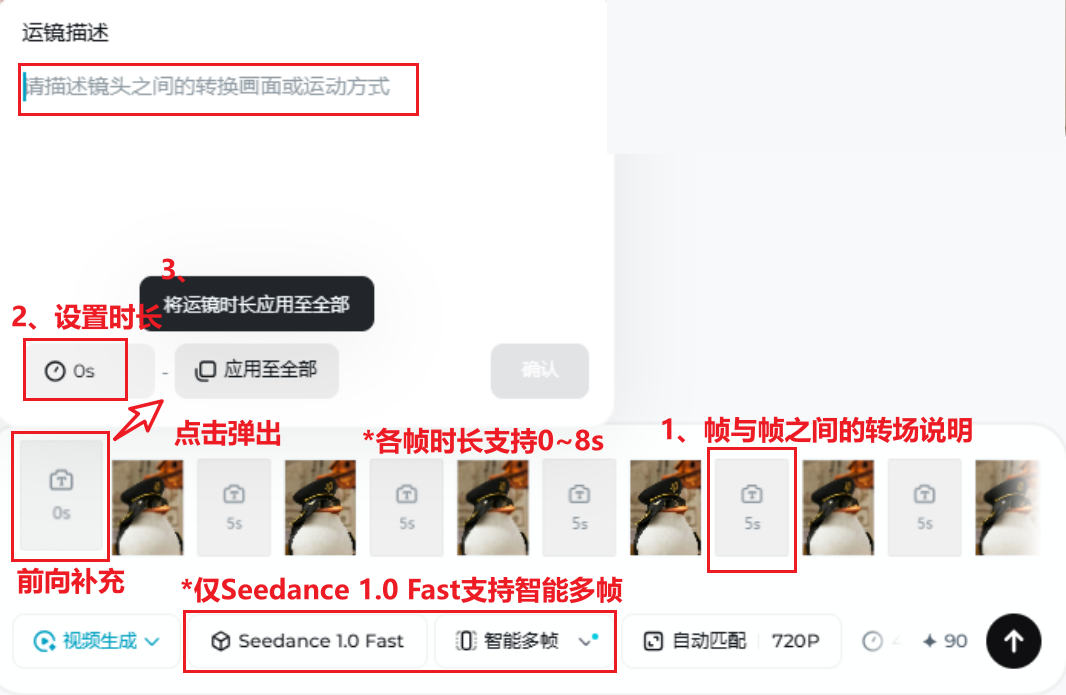
对照上表「智能多帧」一行:在模型区选择支持该模式的版本后,用多张关键参考图约束同一段内的连续动作或教程分步。下图为智能多帧界面示意。
目前仅 Seedance 2.0 支持智能多帧;切换其他模型时入口可能不显示或能力不完整,以客户端为准。
智能多帧介于「单图驱动」与「严格首尾两帧」之间:可上传多张关键参考图,在同一段生成里约束连续动作、走位或教程分步,由模型做帧间衔接。适合小节拍变装、连续姿势、分步操作演示等。能力边界与上传张数以界面说明为准。
📐 4.2 画面比例与分辨率
比例要与发布平台一致,否则会出现黑边、裁切或模糊放大。下图为比例/分辨率选择区域截图,选项名称以你当前客户端为准。
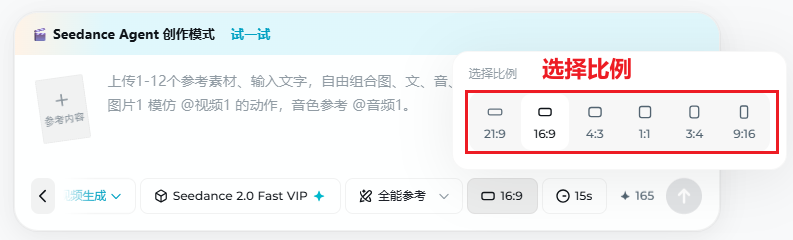
常用比例推荐
| 比例 | 适用场景 | 说明 |
|---|---|---|
| 21:9 | 电影感、宽银幕、桌面壁纸向短片 | 横向极宽,上下易留黑边;上传前确认平台是否裁切或压黑边 |
| 16:9 | B站、YouTube、横屏信息流、课程录屏 | 叙事与风景类最常用,通用横屏首选 |
| 4:3 | 传统横屏、部分电视/教育类、复古质感内容 | 偏「老式显示器」比例,适合怀旧、访谈、幻灯风画面 |
| 1:1 | 小红书方形、部分电商主图视频、信息流方图 | 主体居中构图最稳,多平台方图位通用 |
| 3:4 | 小红书竖版图文视频、偏竖构图展示 | 比 9:16 略「方」一点,适合图文混排竖版位 |
| 9:16 | 抖音、快手、视频号竖屏 | 移动端全屏竖视频最常用比例 |
实操提示
- 若后续要多平台分发,优先按「主发布平台」定比例,再在其他平台用剪辑软件裁切。
- 界面若提供分辨率档位,建议与积分说明一并阅读后再选。
选错比例不会必然失败,但会浪费积分与时间;不确定时先用平台默认竖屏或横屏最常见规格试一条。
⏱️ 4.3 时长与积分
即梦 AI 视频单次生成时长一般在 3–15 秒 内按界面档位选择(具体分档以客户端为准)。时长越长,模型要预测的时间轴越长,通常积分更高、排队更久。建议先写清这一段要发生的动作与镜头量,再选「能演完」的秒数:口播、台词类务必先定稿,按语速反推时长;动作多、转场多的镜头宁可拆成多段生成再在剪映拼接,比硬拉一条长片更稳。下图为时长选择区域截图。
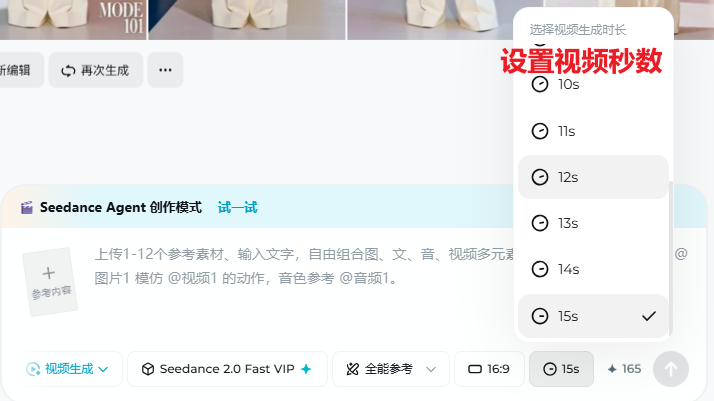
| 时长区间 | 适合做什么 | 建议 |
|---|---|---|
| 3–6 秒 | 单镜头展示、产品特写、表情/口型特写、微动效 | 提示词只写一个清晰动作,易一次过;在 3–15 秒范围内偏省积分 |
| 7–10 秒 | 常规短视频单镜、简单起承、短旁白一句带过 | 新手优先尝试的「中段」区间;先验证人物与运镜稳定再考虑加长 |
| 11–15 秒 | 同镜内多动作、小段落叙事、配乐一句段 | 贴近当前上限,提示词要克制、镜头不宜堆太多;仍不稳时拆镜更可靠 |
🚀 4.4 Seedance 2.0 旗舰视频模型
Seedance 2.0 是即梦平台的旗舰级视频生成模型,支持四种输入模态,实现导演级精准控制:
| 输入类型 | 支持格式 | 数量限制 | 大小限制 |
|---|---|---|---|
| 📷 参考图像 | jpeg、png、webp、bmp、tiff、gif | ≤ 9 张 | < 30 MB |
| 🎥 参考视频 | mp4、mov | ≤ 3 个(总时长≤15s) | < 50 MB |
| 🎵 音频素材 | mp3、wav | ≤ 3 个(≤15s) | < 15 MB |
| ✍️ 文本提示词 | 自然语言描述 | 无限制 | — |
⭐ 六大全能参考能力
精准还原画面构图、角色细节与整体风格
多模态高控制核心能力之一:完整学习镜头语言、复杂动作节奏
长叙事必备:向后或向前延长,构建完整叙事
对已有视频进行角色更替、删减等编辑
声画一体增强:生成视频时自动搭配音效或背景音乐
上传音频素材后,视频动作跟随音乐节拍
📖 4.5 官方文档 — 即梦 Seedance 2.0 使用手册
以下是即梦官方发布的 Seedance 2.0 完整使用手册,强烈建议结合本手册一起阅读:
📌 来源:即梦官方 · 飞书文档